How artificial intelligence works: a simple explanation of large language models (LLMs)
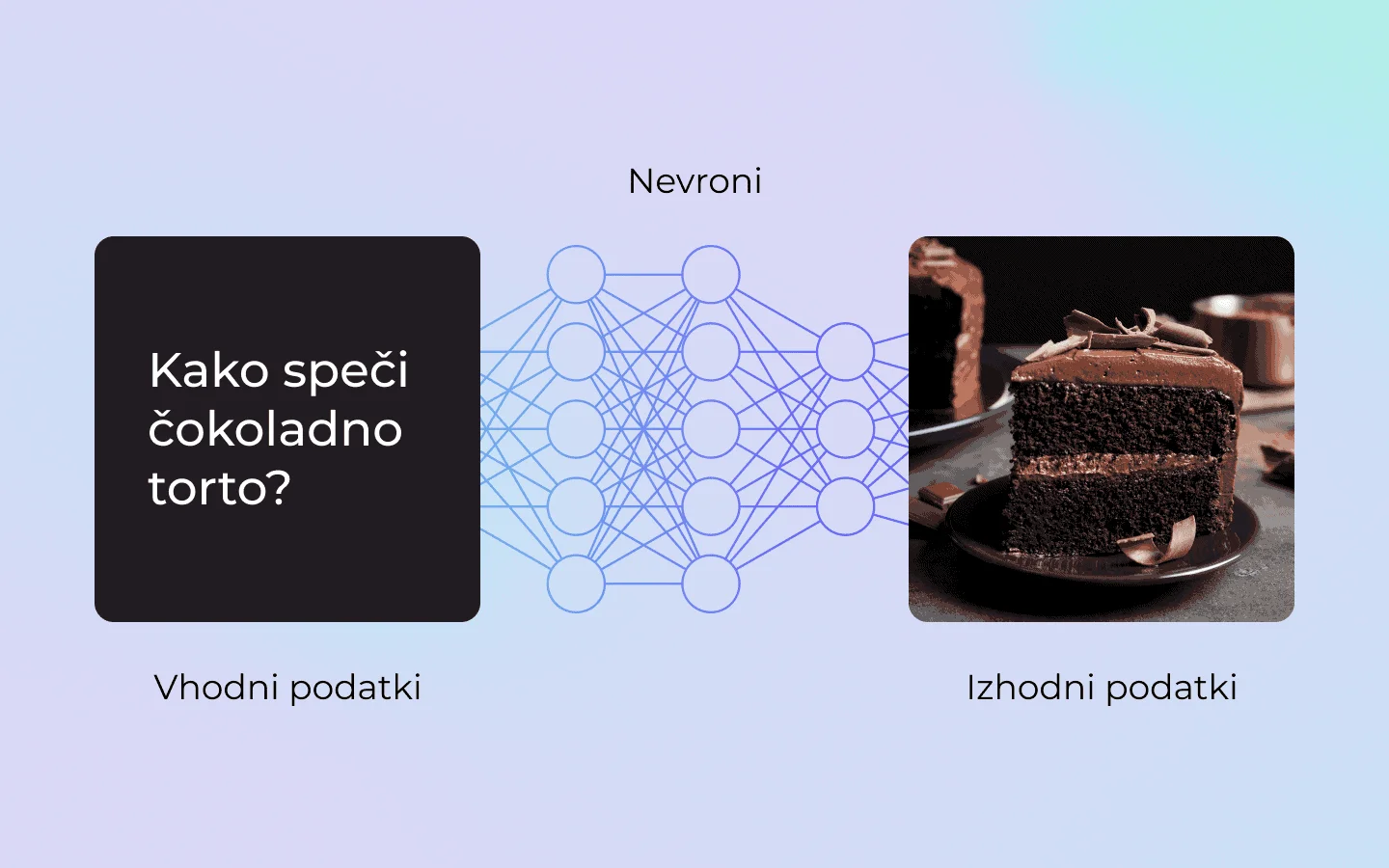
Imagine a kitchen where each chef has a clearly defined task. One chops vegetables, another stirs the sauce, a third adds spices, and at the end the head chef tastes the dish and checks whether it is tasty enough. If the dish isn’t right, say it is too salty, the head chef sends a message back to all the chefs to adjust their work. That is how large language models (LLMs), like ChatGPT, work, where the chefs are essentially layers of neural networks.
The basics of how an LLM works: master chefs in action
1. Input data is the ingredients
Just as a cake needs basic ingredients like flour, sugar and eggs, large language models (LLMs) need input data, called the ‘input/prompt’. This data can be words, sentences or images, like the ingredients the model uses to ‘prepare’ a response. For instance, if we give the model a question like ‘How do I bake a chocolate cake?’, that is its input data, the ingredient it will process to produce a useful and meaningful response.
2. Each chef has their own task
- The first chefs (lower layers): they check the basic features of the ingredients. For example, whether the flour is fine or coarse, and whether the sugar is white or brown. In the world of LLMs, these layers recognise basic features such as curves, patterns, individual letters or words.
- All the chefs in the middle: they start mixing the ingredients and shaping the base. In a cake, that means preparing the dough; in an LLM, it means understanding the meaning of symbols and sentences.
- The last chefs (higher layers): they take care of the decorations and the final details. In language, this means the model creates the whole response, a meaningful whole.
3. The head chef (the ‘softmax’ layer) tastes the dish
At the end of preparing the dish, the head chef (the ‘softmax’ layer) checks: is the dish good? Is the cake the right shape? Does it have the right amount of sugar? Is the flavour balanced? If the chef isn’t satisfied with the result, they send a warning back to all the chefs (layers) to adjust their work. This adjustment process is called ‘backpropagation’ and is key to training models like LLMs.
How does ‘backpropagation’ work?
- Error assessment: the main layer (softmax) calculates the difference between the expected and the actual result. For example, if the cake isn’t sweet enough, the chef works out that the amount of sugar is too low. With an LLM this means the model assesses how its response differs from the correct response.
- Sending the error back, adjusting the weights: the error is sent back through all the layers of the model. Each layer (chef) looks at how it contributed to that error. For instance, the chef who added the sugar realises there was too little of it and improves next time. In the model, this means that the weights of the neurons that contributed to the wrong calculation are adjusted.
- An iterative process: the ‘backpropagation’ process repeats with every new example. With each round (iteration) the model reduces the error, until the answers are accurate and useful enough.
Why is ‘backpropagation’ so important?
- Learning from mistakes: ‘backpropagation’ allows the model to learn directly from its mistakes. Instead of a programmer manually adjusting each layer, the model itself works out how to improve its parameters.
- Automatic optimisation: the model doesn’t need predefined rules for every task. Through this process it learns how to turn input data (the ingredients) into the expected output (a good dish).
- Universality of models: ‘backpropagation’ also makes it possible for the same model to work for different kinds of tasks, from image recognition to language understanding. Adjustments based on errors make the model universal and adaptable.
An example from the kitchen:
Let’s say we are baking a cake and the finished cake comes out too hard as the end result. The head chef works out that the problem is in the dough, too little flour or too many eggs.
The error is communicated back to the chefs:
- The flour chef adjusts their amount.
- The egg chef reduces the number of eggs used.
- The chef who mixes the dough perhaps takes care of more even mixing.
On the next attempt these adjustments will be taken into account, which improves the chances that the cake will be softer and tastier. In a similar way, the LLM model works out how to improve its responses until they become as accurate and useful as possible.
‘Large language models aren’t databases. They are the result of machine learning, where mathematical representations are created by analysing patterns in data. LLMs don’t store data as copies. They use learned patterns to shape unique and useful responses. That is also why proving copyright is difficult, since the models don’t reproduce data but produce responses out of their understanding/knowledge.’
An introduction to the architecture of large language models (LLMs)
Large language models (LLMs), like ChatGPT, are masterfully designed architectures that allow computers to understand and create content for people. They work like a precisely coordinated kitchen, where every ‘chef’ (a neuron or a layer) has its own task. For this ‘kitchen’ to work properly, we need a plan, an architecture, that defines how many chefs will be involved, how they will communicate with one another, and how their tasks will be organised.
Architecture is the heart of an LLM, since it determines how the model processes data, learns, and improves over time. From simple basic layers to sophisticated mechanisms like ‘Transformers’, every part of the architecture contributes to the shared goal: producing accurate, meaningful and useful responses. Let’s see how this architecture works and which key features define it.
Key features of LLM architecture
1. Layers and their hierarchy
The architecture of an LLM is made up of several layers arranged hierarchically.
- Lower layers: they focus on the basic features of the data, such as individual words or short phrases. In text processing this means they recognise individual letters, words, and their meanings.
- Higher layers: they combine information from the lower layers to understand the context and meaning of longer sentences or whole texts.
- The last layer (output): connects all the information and produces the final result, a response, a prediction or another solution.
2. Self-attention mechanism
One of the most important features of an LLM is the ‘attention’ or, more precisely, ‘self-attention‘ mechanism.
What is the ‘attention’ mechanism?
Imagine a chef preparing a multi-course dinner. While cooking, they have to keep an eye on all the dishes at once: check whether the soup is well seasoned, make sure the roast in the oven doesn’t burn, and ensure the side dish will be ready on time. The ‘self-attention’ mechanism works like the chef’s ability to follow all the important parts of the dinner at once, regardless of when they started preparing each individual dish.
For example, the chef started cooking the soup at the very start, but only needs to check it occasionally later on to make sure the flavour is balanced. Meanwhile, the roast is in the oven, and that calls for their attention so they can turn it in time or check that it is browning correctly. Although the soup is an important part of the dinner, the chef understands that at this moment it is crucial to give more attention to the roast, since if it overcooks it can ruin the whole meal.
‘Self-attention’ works in a similar way: it lets the model recognise which part of the data is most important at a given moment for understanding the overall context, even if some parts of the data were processed earlier. In this way it can connect all the key elements and create a meaningful whole.
3. ‘Feedforward’ networks
While the ‘attention’ mechanism connects key parts of the data and decides which are most important for understanding, ‘feedforward’ networks process this data in a more structured and systematic way. ‘Feedforward’ networks act as an additional step, where after each round of ‘attention’ the data is further calculated, refined and prepared for the next layer of the model.
Imagine a chef preparing dough for a cake. First they mix all the ingredients (like ‘attention’, which connects the key information), then they knead the dough (‘feedforward’ network) so that all the ingredients are evenly distributed and the right texture is achieved. If the chef skipped the kneading step, the dough could remain lumpy and wouldn’t be ready for the next step, baking.
Similarly, in an LLM, ‘feedforward’ networks make sure that the information from the ‘attention’ mechanism is further processed and adjusted before it is passed on to the next layer. This step is key to ensuring an accurate and complete understanding of the data.
4. Positional encoding
Since ‘self-attention’ doesn’t understand the order of data on its own, the architecture uses positional encoding to help the model recognise the order in which parts of the data are arranged. This is the way the model understands the order of the elements, which is crucial for preserving their meaning.
Imagine a chef preparing a recipe for a cake. If they had all the instructions on paper but with no order (‘add flour’, ‘put it in the oven’, ‘whisk the eggs’), they could mistakenly put the cake in the oven first and only then add the flour, which would ruin the result. Positional encoding is like numbering the steps of a recipe, ensuring that the chef first mixes the ingredients, then prepares the dough, and finally bakes it.
In a model, positional encoding works in a similar way: it helps determine how the data parts (e.g. words or elements) are ordered, so that their meaning and proper sequence are preserved during processing. This way the model can understand not only the individual parts but also their relationship within the whole.
5. Transformers: the foundation of modern LLMs
Transformers are the architecture that forms the foundation of modern large language models (LLMs). Their design enables fast, efficient and adaptable data processing, which is why they have become the standard for natural language processing and other complex tasks.
The key advantages of transformers include:
- Parallelisation: transformers allow data to be processed across multiple layers at the same time, which considerably increases speed. Instead of processing data sequentially (as in older architectures), transformers can analyse several parts of the data simultaneously (in parallel), which speeds up training and the generation of results.
- Effective learning: by using ‘attention’ and ‘feedforward’ networks, transformers accurately understand long-range relationships in the data. For example, they enable the model to understand how a word at the beginning of a sentence affects the meaning of words at the end. This ability is key for understanding complex structures and contexts.
- The ability to scale: transformers can contain billions of parameters, which means they are capable of handling exceptionally complex tasks. By increasing the number of parameters, models like ChatGPT can understand a broader context, produce meaningful responses, and adapt their capabilities to a variety of tasks.
Imagine a restaurant preparing several different dishes for guests at the same time. Transformers are like a well-coordinated kitchen team, where each chef can work on their part of a dish at the same time (parallelisation). While one prepares the vegetables, another cooks the soup, and a third bakes the dessert. Each chef monitors how the whole meal is progressing and adjusts as they go (effective learning), so that all the dishes are ready at the right time.
On top of that, the kitchen is set up so that it can handle ever larger numbers of orders. For example, more chefs and tools mean the restaurant can serve even more guests (the ability to scale). Transformers work in a similar way, since they allow the model to process larger volumes of data and more complex tasks without losing efficiency.
6. Normalisation: stability in data processing
In large language models (LLMs), normalisation is key to ensuring that information flows through different layers efficiently and without problems. Normalisation works by keeping data values in a balanced range, which prevents them from becoming too large or too small, since that could hinder learning and reduce the model’s reliability.
How does normalisation work?
Normalisation makes sure that the input data and the outputs of each layer are adjusted in a way that allows stable and effective learning. It prevents problems such as:
- Excessively high values: the data can become ‘overloaded’ and the model struggles to understand which information is important.
- Excessively low values: information can be ‘lost’, which means the model doesn’t pick up key patterns.
Normalisation works as a method for balancing these values, ensuring that the model behaves stably and converges quickly toward correct solutions.
Imagine a chef preparing dough for a cake. If, when mixing the ingredients, they add too much liquid (milk) or too much dry matter (flour), the dough won’t have the right texture, it will be either too runny or too stiff. The chef must precisely balance the quantities of the ingredients to achieve the right consistency.
Similarly, in an LLM, normalisation works as a process of balancing (‘weights’) that ensures the data (or ‘ingredients’) are in the right ratio, enabling the model to process information effectively and produce accurate results. Without this step, data in certain layers could become too extreme and make further processing harder.
7. ‘Dropout’: preventing overfitting
‘Dropout’ is a technique used in large language models (LLMs) to regulate learning. It helps prevent the model from relying too heavily on individual neurons or features in the data, which could cause overfitting to specific patterns in the training data. At each step, a random subset of neurons is ‘switched off’, forcing the model to develop more general and adaptable solutions.
How does dropout work?
Dropout works by temporarily removing some neurons from the data processing during training. This means that a certain percentage of neurons don’t take part in the calculations.
- During training: the model is forced to use other neurons to perform the task, which leads to more dispersed learning and prevents over-reliance on a particular part of the network.
- During use: once the model is trained, dropout is no longer active, which means all neurons contribute to the final result.
Imagine a kitchen where, while preparing a meal, a chef realises they are missing a tool, for instance a spatula for mixing. Instead of giving up on the dish, they find other ways of mixing, for example with a spoon. In this way they improve their adaptability and learn to use different tools to reach the goal.
‘Dropout’ works in a similar way: by temporarily removing certain neurons, the model is encouraged to look for alternatives and solutions through other paths. This makes it more robust and less dependent on individual neurons or data features. As a result, the model becomes more capable of handling new, unfamiliar tasks.
Why is architecture so important?
Architecture is the foundation that makes LLMs work. Each layer, mechanism and technique contributes to the model’s ability to understand the data and improve. Just as a well-designed kitchen enables coordinated work by chefs, a thought-through architecture allows LLMs to perform tasks accurately and efficiently. Without it, models would become inefficient, struggle to understand the data, or simply produce low-quality responses.
Why are large models possible only now?
Although concepts like neural networks and artificial intelligence have been known for decades, only in recent years have we seen the rise of large language models (LLMs). This is the result of a combination of technological progress, new algorithms, and access to large quantities of data.
1. Processing power: modern ‘kitchen utensils’
Only recently have we developed computing devices powerful enough, like GPUs (graphics processing units) and TPUs (Tensor Processing Units), that allow large quantities of data to be processed in parallel.
2. Access to large quantities of data: an abundance of recipes
With the development of the internet, we now have access to enormous quantities of data needed to train models. This data includes texts, images, videos, and other content.
3. Advanced algorithms: smarter chefs
In the past, architectures like RNNs (recurrent neural networks) or LSTMs (long short-term memory networks), were key for processing sequential data, but they had their limitations. Today the Transformers have changed the game.
How do we create and train a large language model (LLM)?
Creating and training a large language model (LLM) can be compared to the process of preparing a complex dish in a well-organised kitchen. This metaphor makes it easier to understand the steps needed to set up an effective and accurate model.
Setting up the architecture (the kitchen)
- Determining the number of layers (chefs): first we set the basic structure of the model. This includes choosing how many layers the model will use to process data. More layers usually mean a greater ability for the model to learn complex patterns.
- Setting the rules of communication (the types of layers and activation functions): each layer has a specific task. Layers can be of different types, such as convolutional (for image analysis), recurrent (for processing time-related data) or transformational (for working with different types of data). Activation functions, in turn, decide how layers communicate with one another and process the data.
Each layer in the model is like a chef with a specific specialisation, for instance for chopping, stirring or cooking, while activation functions are the rules that determine how they work together in a coordinated way to prepare the dish.
Preparing the data (the ingredients)
- Collecting an extensive dataset: data is the basic ingredient of every model. We prepare it in large quantities and with diverse content, such as texts, images, sound, translations or data tables.
- Learning by example: we present the model with millions of examples so that it recognises relationships and patterns among the data. This process allows it to develop the ability to draw conclusions from input information.
The training process (the cooking)
- The starting phase: at the beginning, the model’s parameters are set randomly, which means the model produces unrelated and often wrong results.
- Correcting errors (‘backpropagation’): when the model produces a wrong result, the error is analysed and used to adjust its parameters. This process allows the model to gradually improve its accuracy.
- Repetitions: training the model takes place over thousands or even millions of repetitions. This makes sure that the model gains the ability to recognise and process even the most complex patterns.
Adjustments and improvements
- Human evaluation: the model’s results can also be assessed by people to verify their quality and usefulness. This step ensures the responses meet expectations.
- Additional training (‘fine-tuning’): ‘fine-tuning’ is a process in which an already trained model is further adapted for specific tasks, such as photo analysis, translation, or music creation. This is achieved by using a smaller, target-oriented dataset that teaches the model to perform better on a particular type of content or problem.
- Continuous learning: after the basic training is finished, the model can be updated with new data, or given access to external sources such as the internet. We can also use feedback from users to improve the responses and adapt the model to their needs. Such updates allow the model to remain useful and adapted to new requirements.
Why are large language models (LLMs) so important?
Large language models (LLMs) represent an important step forward in the development of artificial intelligence. Their impact reaches across many fields, since they enable the solving of demanding tasks involving the understanding, processing and creation of information in different forms. Their versatility and advanced design place them at the heart of modern technologies based on artificial intelligence.
The versatility and usefulness of LLMs
LLMs have an exceptional ability to adapt to different language tasks, which makes them indispensable in various sectors and applications. Their capabilities include:
- Answering questions: providing fast and accurate answers based on extensive knowledge gained during training.
- Writing texts: creating articles, reports, stories or even creative content, such as poetry.
- Summarising articles: turning long and complex content into shorter, concise summaries.
- Multilingualism and translation: understanding and generating content in several languages, which makes communication and translation easier.
LLMs aren’t limited to text alone, however. Similar approaches make it possible to use these models for processing images, sound and other types of data.
Three key features that define their importance
- Extensive knowledge of language: LLMs learn from huge collections of data that include different kinds of content, from scientific articles to conversations on social media. In this way they gain a broad understanding of language patterns, structures and contexts, which lets them solve tasks in a variety of environments. Based on this knowledge, they can produce responses that are clear, logical and adapted to the user’s specific needs.
- Adaptability and constant improvement: after the basic training is over, LLMs don’t, on their own, adapt to new data or changes. Their adaptability depends on planned interventions, such as retraining with current data, the inclusion of feedback from users, and access to external sources of information, for instance the internet. Without these updates, the model remains static and doesn’t reflect novelties or changes from the real world.
- Advanced algorithms for accuracy and efficiency: LLMs are based on the most modern methods of deep learning, such as transformer models. These algorithms ensure that the responses they offer are not just accurate but also meaningful and understandable for the user. Their ability to draw conclusions and connect different pieces of information goes beyond mere surface-level processing of data.
Conclusion: an invaluable tool of the future
Large language models are an essential part of the future of artificial intelligence. Their ability to solve complex tasks, their adaptability and accuracy place them at the centre of technological progress. Just as a top kitchen can prepare a dish for every taste, LLMs offer solutions that range from everyday questions to the most demanding challenges. Their value lies in their ability to connect extensive knowledge with the practical needs of users.